Motivation
I’ve seen projects where people bring x technology to devices that existed long before the technology existed. For example, while writing this, I learned about Web Rendering Proxy (WRP) which renders websites as a GIF or PNG but uses HTML image maps to allow the client to interact with the webpage. Email is a technology that’s been around since 1971 and will likely continue to be prevalent. Thus, making an email chatbot that used Large Language Models (LLMs) to generate responses seemed cool. In addition, with various educational institutions and workplaces blocking access to LLMs, such as OpenAI’s ChatGPT, email could theoretically be used to bypass these restrictions. However, it probably would be more effective to just use another client that isn’t blocked.
Challenges during development
The most challenging aspect of building an email-based chatbot is the need to track replies. At one point, I had retrieved email threads by going up the ladder of In-Reply-To headers. However, this led to poor performance. The user’s emails were already being tracked and there was really no need for this. During development, I had forgotten that emails were already being tracked. The only issue was that only the user’s emails were being tracked. This was due to, depending on the email provider, emails not being in the primary inbox. Thus, the most optimal solution that I arrived at was to add the ability to specify one or more folders via a command-line argument or an environment variable. For Gmail, only [Gmail]/All Mail needs to be used as that includes both sent and received emails. However, for some providers, such as Outlook, multiple folders need to be specified, such as Inbox and Sent. Without the ability to access sent emails, the bot’s messages aren’t passed to the LLM leading to an incomplete conversation history.
Another, slightly humorous mistake was me forgetting that I was running a second instance of the bot in Docker in the background. I spent some time debugging why the bot was responding twice to emails. I was also confused as to why the bot was using a system prompt that I was no longer using. However, I eventually realized that I had been running another instance of the bot in Docker with an old system prompt.
Adding phidata
Heads up: as of 2025, Phidata now seems to be called Agno.
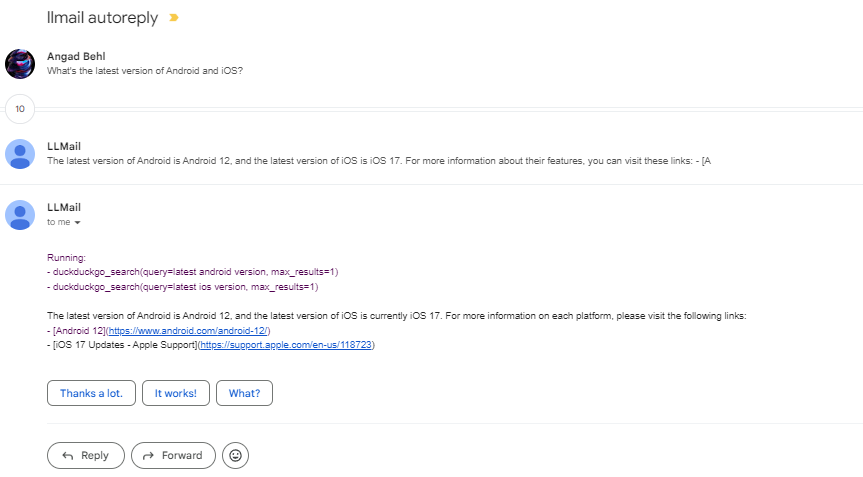
Phidata, as once stated in the README, is “a framework for building Autonomous Assistants (aka Agents) that have long-term memory, contextual knowledge and the ability to take actions using function calling.” Initially, I put off implementing phidata as I was unsure if it would work without powerful hardware or paid APIs. However, I eventually decided I should just try it out. Whilst it worked, it didn’t work as well as I would have hoped. In addition, it didn’t seem to work with OpenRouter
which I had been using to handle the LLM part of the bot due to its free tier. Thus, I used Ollama running locally on my laptop with an RTX 3070. Llama 3 performed rather poorly with function calling. However, mistral:7b-instruct-v0.3-q6_K performed well and was fast as well. Either way, in my testing, the LLM was unable to get fully accurate information when searching the web through function calling. However, web scraping worked quite well. In the screenshot below you can see the bot correctly stating the latest iOS version but incorrectly stating the latest version of Android. I was deleting emails in the account the bot was accessing via IMAP, so the bot could reply without me having to start a new thread, leading to the multiple emails from the bot in a row.